
推荐文章
热门文章
- 1[推荐]南京师范大学计算机与电子信息学

南京师范大学是教育部与江苏省人民政府共建...
- 2喜报!我院计算机学科进入全球ESI

在第37个教师节来临之际,我院计算机学科进入...
- 3我院研究团队在《Research》发表
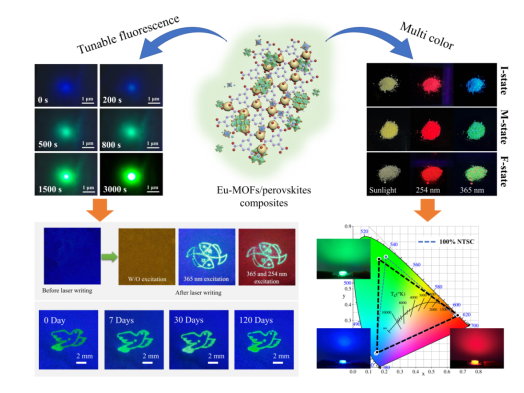
金属卤化物钙钛矿半导体因其独特的光学和电...
- 42017年上半年计算机学院硕士研究
2017年上半年计算机学院硕士研究生学位论文...
2024年10月12日,由中国计算机学会计算机视觉专业委员会主办、南京师范大学计算机与电子信息学院/人工智能学院承办的CCF-CV“视界无限”系列研讨会——“以人为中心的视觉感知:由表及里”在南京师范大学芳菲楼报告厅圆满举办。此次会议特邀南京师范大学学科建设处处长张晓锋教授及中国计算机学会计算机视觉专业委员会秘书长王瑞平研究员发表致辞。张晓锋教授在致辞中介绍了南京师范大学概况,并表达了对此次活动能够有力推动计电学院相关领域研究的深切期望,期待其为计算机学科及其相关学科带来新的灵感与启发。王瑞平研究员在致辞中简要概述了CCF-CV系列学术活动的背景与现状,并对与会的领导、嘉宾、老师及同学们表达了诚挚的感谢,预祝研讨会取得圆满成功。

中国科学院计算技术研究所山世光研究员、中国科学院自动化研究所张兆翔研究员、浙江大学李玺教授、上海交通大学林巍峣教授、南京大学单彩峰教授、南开大学杨巨峰教授做主题报告。在主题研讨环节中,南开大学刘夏雷副教授、清华大学唐彦嵩研究员、香港中文大学唐诗翔博士、南京大学张振宇副教授,分别就各自的研究领域进行了深入的观点分享。此外,多位报告专家与参会的青年学者还围绕相关议题展开了热烈而深入的自由讨论,共同促进了学术的碰撞与交融。会议由南京师范大学钱建军教授、周俊生教授、顾彦慧教授、杨琬琪副教授,以及南京理工大学张姗姗教授等共同主持。
领导致辞

南京师范大学学科建设处处长张晓锋教授致欢迎词

CCF计算机视觉专业委员会秘书长王瑞平研究员致欢迎词
主题报告

山世光研究员的报告以“视线估计与跟踪研究”为题,深入浅出地介绍了两项前沿的视线估计技术:一是利用三维视线估计技术,实现对面部图像的眼神精准跟踪;二是结合二维与三维视线追踪技术,对场景图像中的眼神进行高效捕捉。接着,他分享了其团队在眼神行为分析领域的研究成果,特别是针对自闭症谱系障碍(ASD)儿童的眼神注意分析,以及社交交流中视线行为的深度剖析。最后,山世光研究员还就数据驱动方法在数据收集方面的实践以及当前研究面临训练和测试数据不足等挑战进行了探讨。

张兆翔研究员的报告以“以人为中心的生成式模型初探:由里及表”为题,巧妙地从人工智能和以人为本的角度深入剖析了“里”与“表”的概念,并以此为基,探索构建兼具人性与风格化的智能体。随后逐一详述了角色扮演语言风格模型、角色扮演意识风格模型及角色扮演动作生成模型一系列创新技术路径,针对当前模型的发展现状与存在的关键问题进行了探讨。最后,对由里及表的全方位生成的未来进行展望并强调了由表及里的感知与由里及表的生成之间的双向促进作用。

李玺教授的报告以“多模态视觉结构学习”为题,首先从目标视觉感知特性、视觉特征表达、深度学习器构建机制、高层语义理解等多维度视角进行了深入剖析,并引入了大规模多模态特征学习所涉及的核心研究问题挑战与技术方法。随后,他系统回顾了多模态特征表达和学习领域的发展历程,分享了近几年来其团队利用特征学习进行视觉语义分析与理解方面的一系列代表性的研究工作及其应用,包括球面几何感知的Transformer在全景语义分割中的应用,以及通过语言自适应推理,通过迭代扫描进行引用表达理解等。最后李玺教授还深入探讨了多模态特征学习当前面临的开放性问题与难题。

林巍峣教授的报告以“语义驱动的大规模视频内容感知与编码”为题,首先介绍了目标行为与事件语义提取方面的工作,通过重构当前行为事件识别与定位的框架,提出了从全局至局部的渐进式行为事件提取架构。紧接着,他深入阐述了复杂事件步骤对齐及因果推理的研究进展,通过对复杂事件的步骤挖掘、对齐实现对目标对象和事件类型的感知,并对事件中的因果逻辑进行推理分析实现对视频中复杂事件的全面理解。此外,林教授还详细介绍了其课题组在语义信息压缩编码领域的研究成果,设计了一套针对关键点序列及因果关系图等核心视频语义内容的压缩编码架构,实现了对象、交互、事件多层次语义的高效联合编码。最后,他分享了这一研究方向在实际应用场景中的广阔前景与案例。
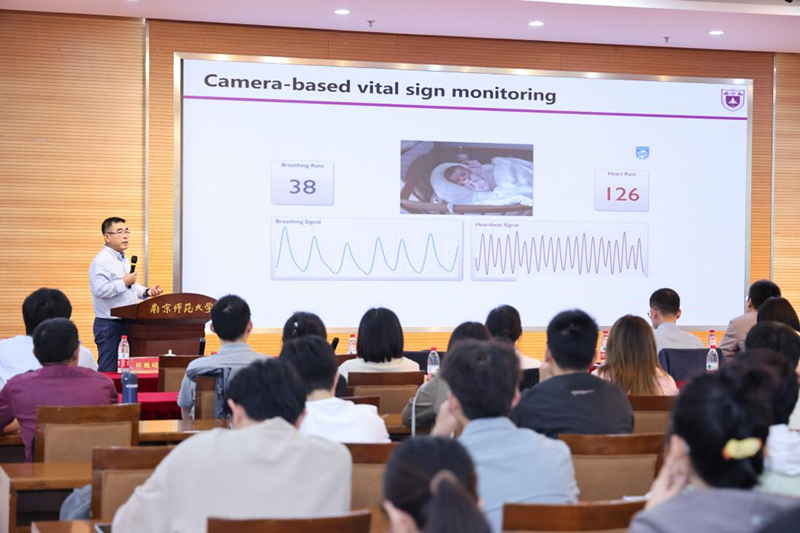
单彩峰教授的报告以“Camera-based Physiological Measurement”为题,首先介绍了基于相机的非接触式生命体征监测技术的研究背景,并着重阐述了非接触式光学成像相较于传统接触式生物传感器的显著优势。随后,他详细列举了该技术的实际应用场景,包括新生儿远程心率(HR)监护、血压测量、灌注检测、体内器官组织的血液流动情况等等,这些应用已在多个复杂的医疗场景中验证了非接触式多维生命体征监测的可行性。紧接着,单教授分享了其团队最新的研究进展,提出了Camera-SCG技术,该技术利用激光干涉现象构建三维离焦散斑探测系统,实现了对心脏三维运动的精准非接触光学重建。最后,他探讨了非接触式生命体征监测研究中所面临的诸多挑战,为与会者提供了宝贵的思考与启示。

杨巨峰教授的报告以“情智兼备数字人与机器人关键技术初探”为题,首先深入剖析了该科学问题的起源与背景,全面分析了国内外相关机构在智能与情感机器人领域的研究现状,通过对比两者的发展历程,阐述了情智兼备的数字人与机器人在未来科技中的重要地位及其所面临的关键难题与挑战。紧接着,杨教授提出了四个可研究方向,包括情感机理研究、情感大模型、多模态情智融合解译、个性化情感表征与动态计算。然后,他分享了其课题组在情感智能领域的最新研究工作与初步成果,包括基于AU拖拽的人脸表情编辑、表情包生成、文本生成幽默图像等。最后,杨巨峰教授对情智兼备技术的一体两面及其蕴含的研究机遇进行了深刻探讨,为与会者提供了宝贵的洞见与启发。
主题研讨
观点分享

刘夏雷副教授在题为“基于图文预训练模型的连续学习方法研究”的报告中表示连续学习是新一代人工智能系统的关键技能之一,阐述连续学习的概念并指出其面临最大的挑战--灾难性遗忘,随后以图文预训练模型为基础,探索以知识引导的连续学习方法的研究,并分别从判别性模型与生成性模型两个角度,深入剖析并展示解决连续学习难题的新思路。最后对连续学习领域进展进行总结和展望。
唐彦嵩研究员在题为“关于人体动作理解与生成的一些思考”的报告中表示人体动作理解和生成是计算机视觉领域中的重要问题,首先介绍了不同维度下的人体动作理解任务,通过长时程视频动作问答,关注细粒度人体动作的描述在推理阶段进行更加高效设计。随后介绍了不同控制条件下的人体动作生成方法并展示了音乐驱动动作生成的研究成果,最后对未来人体动作理解与生成领域面临的挑战进行了深刻的思考与讨论。
唐诗翔博士在题为“通用行人检索大模型研究”的报告中指出大规模多模态行人重识别的核心挑战在于构建一个能够支持多样化多模态指令并具备强大场景泛化能力的通用行人检索模型。具体而言,唐博士介绍了通用行人检索模型的一系列研究成果,包括多模态通用行人重识别数据集、行人重识别模型与行人检索大模型。最后对通用行人检索领域关于数据与模型方面的研究方向进行探讨。
张振宇副教授在题为“表里先验引导的三维数字人重建与生成”的报告中首先介绍三维数字人的背景与意义。随后从“表”先验与显式约束、“里”先验的规律探索,以及这两者的统一与结合三个方面,系统介绍了这两类先验在三维数字人重建与生成问题中的重要应用。并且深入分析了这两类先验的适用性,指出了在解决三维数字人重建与生成难题中的独特优势,同时也讨论了它们可能带来的局限性与挑战。最后对三维数字人重建与生成技术的未来发展进行了总结与展望。
自由讨论
本次研讨会邀请了李玺教授、单彩峰教授、林巍峣教授、杨明教授、刘夏雷副教授、唐彦嵩研究员、唐诗翔博士、张振宇副教授进行自由讨论。对话由张姗姗教授主持,以下为讨论纪要。

张姗姗教授(主持人):在深度学习兴起之前,计算机视觉领域就有很多研究,并且以人为中心的视觉领域其研究历史更为久远。但实际上在不断演进的过程中特别是深度学习兴起之后,一些Topic就开始渐渐淡出舞台。那么我们应该怎样随着不断涌现的热点去选择一些新的任务或者一些新的问题来进行研究,我想请各位老师结合自己的研究的子领域来给大家分享一下。
林巍峣教授:结合视频分析与压缩的研究方向,首先从视频分析这个领域来看,我觉得现在很多新的技术总是发展到最后才能解决事情当中的问题,那么有一点我们可以准备的是借鉴其他领域相关做法再慢慢地应用于本领域上。比如现在大模型在很多领域表现非常好,但实际上今天介绍的因果推理也是到了最后还没有很好的解决方法,所以我们其实可以借鉴其他领域方法再去做这些课题。在压缩领域其实还不太一样,因为曾经有一度停滞,而最近深度学习的方法相当于代替原来的机制,所以我们最近又发现可以去做的课题。总之,我感觉在我们的研究中,如果一开始研究方向多,那选课题自由度则会大,即使有些课题可能暂时会停滞,但其他方向可能还会有所进展。
李玺教授:现在科研变化快,企业导向明显,大家更多是在基础上做一些应用,易导致现在的科研模式变成一个修复工艺、不断提升工艺的问题。从今天的主题以人为中心来看,我们要看每个学生的最终目的是做了一个模型、一套算法,或者其他应用,能否反馈到人类世界并起到作用。第一点,我们在追求一个细节的创新,还是追求一个解决方案的创新,或者还是集中追求一个问题发现的创新,因为每个维度不同,所以在这个过程中一定要针对自己的擅长来做。第二点是不忘初心,我建议研究的最终目的是希望能够反馈到这种真实的物理问题上,研究是否推动了领域进步,而不是只是为了制造一个新问题。第三点学生应定位清晰,培养自身能力,包括工程学习、沟通、总结能力等。在寻找研究方向上,多跟导师一起沟通。个人建议重视基础,建立科研模型,制定适合个人的科研范式。
单彩峰教授:可能我的经历跟刚才林老师和李老师不太一样,我是博士毕业之后直接去的工业界,公司研究院,首先我觉得更多的人现在是可以做 AI与其他方向和学科一些交叉,现在基本上各行各业都可以从这个角度来做。所以我给大家的建议是,拓宽自己的视野,寻找学科交叉点,这应该是高校很多年轻老师或者学生的一个思路。第二个我觉得现在的导向而非仅追求发表论文,最终导向应是要解决实际问题。如果只是为了发表一篇论文,研究就会比较局限。
张振宇副教授:我挺同意单老师和李老师所表述的一些观点,因为我本身也是从工业界回到学术界的,在工业界都是业务导向的,有很明确的业务决定你要做哪些事情。所以说第一点在当前强调研究实用性的大环境下,选择研究课题应从实际使用场景出发。通过与企业的接触,可以明确哪些问题是业务中的卡脖子问题,从而确定研究方向。第二点是要走出去,在遇到研究瓶颈时,应尝试与新的思潮结合,以寻求突破,将不同领域的知识和技术进行融合和创新,从而找到新的解决方案。第三点是深入思考本质,只有对问题的本质有深刻的理解,才能找到更具生命力的解决方案。虽然不同技术的发展时期会有不同的针对性策略,但抓住问题的本质是关键。其实说的简单,但是做起来比较难,还是需要大家在过程当中不断地去思考,谢谢大家。
刘夏雷副教授:前面几位老师讲的都非常好,我个人的研究方向是开放环境视觉连续学习,尽管其应用落地目前尚不广泛,但我个人认为它是未来模型可能依赖的关键技术。所以我也是希望自己能够坚持在这个方向做一些探索。我的建议一是在研究过程中不断与最新方法理论结合,以拓展特定的研究方向。二是当研究达到一定阶段,积累足够经验后,可以在基础领域周围进行探索,以拓宽研究视野。我后面也希望能够有更多的交叉来做更多的工作,这是我的一点看法。
唐彦嵩研究员:前面几位老师说得非常好,我想从从学生角度来讲,首先第一点还是需要去跟导师做充分的沟通,因为导师是大家在学生期间非常重要的领路人,第二点是每个同学自己之后的发展路径也不一样,如果是要去工业界的话,在做事情的过程中多去积累相关方面的能力和经验,如果是想走学术的道路,那么可以在做相关的事情时,多去思考背后的学术意义,看得更远一些,例如十年、二十年后又是怎样一个发展的态势。
杨明教授:结合一些新的技术,可能就比原来做得越来越好,计算机视觉可能按照这种方式去做,我想问一下就是说机器学习是不是能够按照这种思路去做?
李玺教授:我觉得这个问题是一个比较开放的问题。我个人的观点是机器学习偏向于偏学习方法和手段,而计算机视觉则更侧重于应用。这两者之间存在一个连接点,即工具与应用之间的平衡。工具追求通用性,而应用则追求专业性和深度。然而,当前机器学习主要依赖数据驱动和统计学方法,这在某种程度上遇到了瓶颈。随着数据使用的限制和算法的优化空间有限,传统的学习框架面临挑战。从工具的角度看,当前的学习工具尚未标准化,因为它们严重依赖于数据的分布,无法过拟合所有数据。但从应用的角度看,过拟合是可能的,只要枚举出应用的所有可能空间,就可以实现出色的应用效果。此外,当前的学习架构限制了模型空间,只能在特定空间内进行优化。虽然模型和数据尚未达到其上限,但离真正的物理理解和创造还有距离。当前的学习能力仍然是人类智慧的结晶,需要消化和吸收大量数据。最后,这是一个开放的问题,没有标准答案,需要从多个角度去看待和分析。
张姗姗教授(主持人):今天讨论得非常热烈,我们今天自由讨论环节就到此结束,如果各位在座的老师同学还有问题,还可以线下和我们的各位嘉宾来进行交流。最后我们非常感谢各位嘉宾今天的精彩分享,也感谢各位老师和同学参与我们今天的活动,谢谢大家。

主题研讨--自由讨论环节
研讨会在大家激烈的讨论中落下帷幕。每一位专家的分享都提供了宝贵的思路和启示。希望大家不断探索未知领域,共同应对技术发展的挑战,为实现更加智能、更加美好的世界贡献智慧和力量。

地址:南京仙林文苑路1号 | 邮编:210023